
S3 Batch Operations Copy Objects leverages the power of Amazon S3’s highly durable and scalable infrastructure. It ensures data integrity during the copy process and provides options for configuring error handling and reporting. You can track the progress of your copy operations, monitor their status, and receive detailed reports on any failed copies, enabling you to troubleshoot and address any issues efficiently.
This feature offers several benefits. Firstly, it saves time and effort by allowing you to copy objects in parallel, thereby significantly reducing the overall completion time of the operation. Additionally, it provides a straightforward way to automate the copying process, eliminating the need for manual intervention and enabling you to perform large-scale data migrations, backups, or data processing tasks with ease.
Below, we’ll take a look at an example of generating a Batch Operations task using the AWS Console to do “copy” activities between buckets in multiple AWS Accounts. For our example, we already created the S3 buckets source-batch-operations-bucket and target-batch-operations-bucket.
Step 1: We can create a job after going to the Batch Operation feature page in S3 Console. Here we will provide an S3 inventory file while creating the batch operation job to supply. the list of objects for performing operations. For our example, we have kept the inventory file in the source bucket as seen from the image below.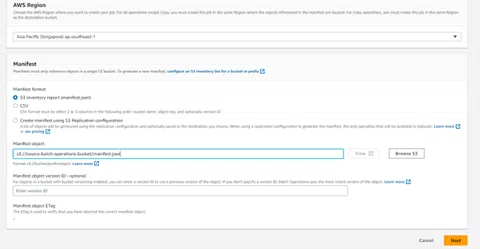
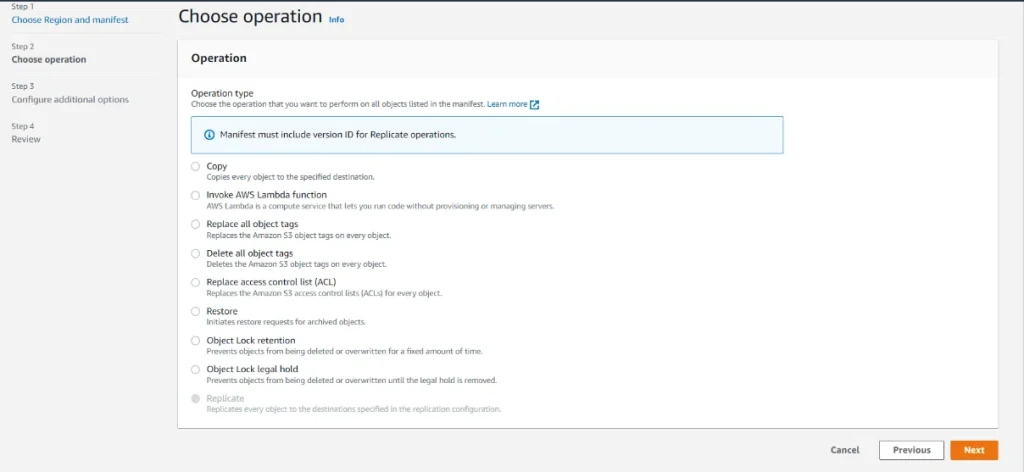
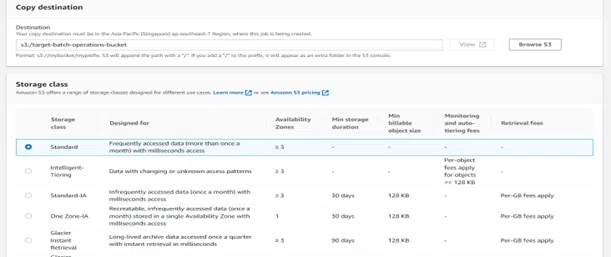
Step 2: The following step prompts you to select the operation you wish to perform on AWS S3 objects. In this situation, we choose “Copy” since we will be transferring things to a separate S3 bucket. You must also provide the destination bucket and storage class for the items in the target bucket.
Step 3: Now select job priority and request a completion report that includes all tasks. For the completion report, a destination S3 bucket needs to be selected where the report will be uploaded. Role ARN or policy document needs to supply to grant permission to access the specified resources in the S3 bucket.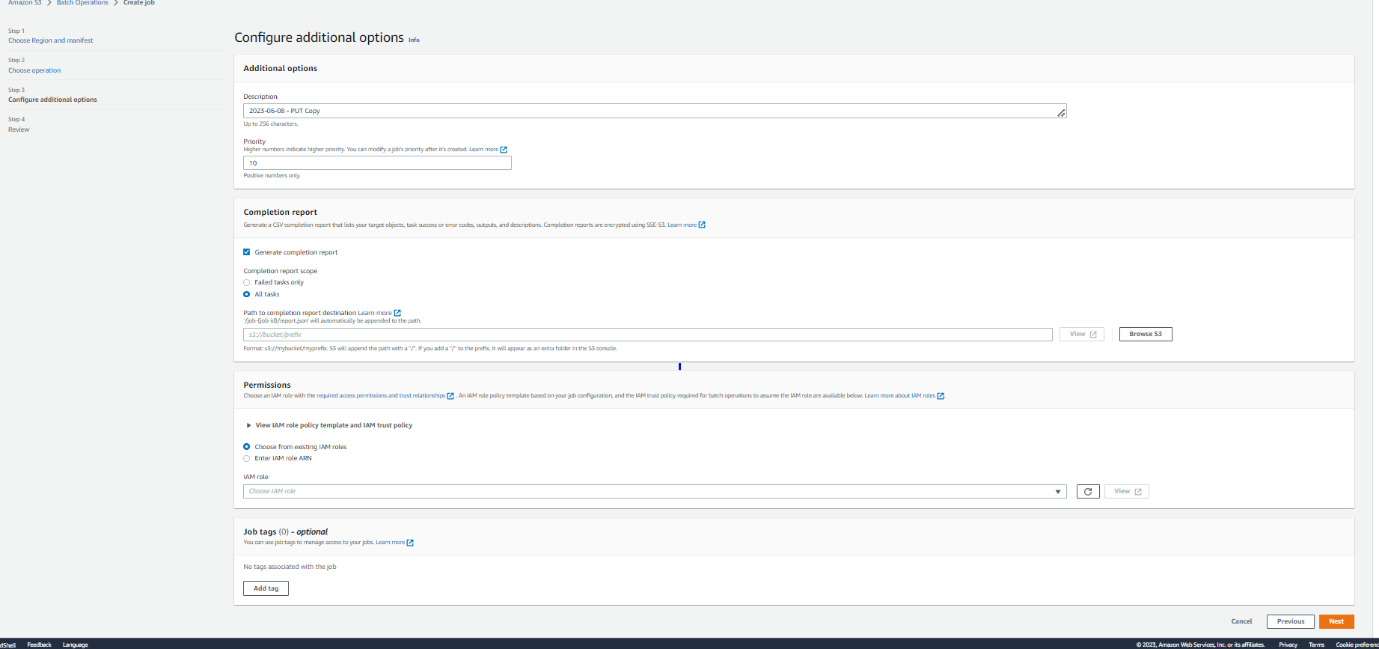
Step 4: Once the information in the previous stages has been reviewed, make sure all the data have been entered accurately. then choose the Create Job option. The task now is to get the state ready. S3 Batch Operations therefore validates the manifest and confirms the settings. Following that, the task goes into the “Awaiting your confirmation” condition. Click on the confirmation box and proceed in parallel to the “Awaiting your confirmation” step.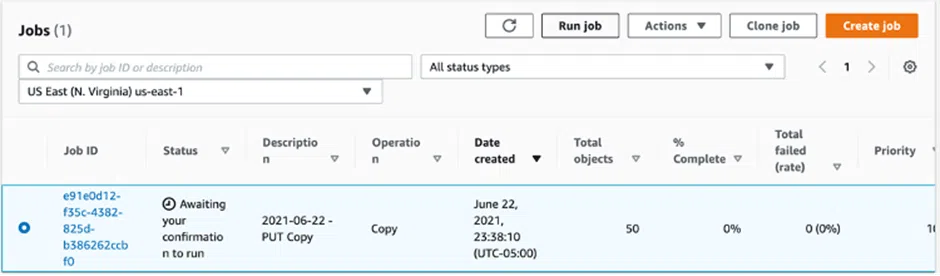
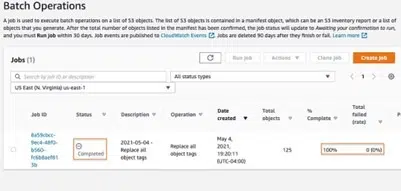
Step 5: Check the status of the job ID, as indicated in the figure below, to see if the job was successfully completed. You may look at your completion report to see the batch operation details for each of your S3 items.
We recently used this feature for one of the world’s leading commercial real estate services and investment solutions providers. We were required to tag objects and to migrate data from one AWS account S3 bucket to another AWS account S3 bucket. There was a huge data of around 65TB with millions of objects in the bucket.
Using S3 Batch Operations, we could be could copy the data quickly across S3 buckets and apply the required tags. There is no need for any custom application/script to be created to do similar operations on S3 objects after AWS introduction of the Batch Operation feature by AWS.


