


Optimize Business KPIs by Making Effective Actionable Decisions Using Causal ML




If an action or treatment(T) causes an outcome(Y), if and only if that action(T) leads to a change in the outcome(Y), keeping everything else constant. Causation implies that by varying one factor, I can make another vary. (Cook & Campbell 1979: 36, emphasis in original).
Example: If Aspirin causes relief to my headache, if and only if that Aspirin leads to a change in headache.
If Marketing causes an increase in sales, if and only if that Campaign leads to a change in sales, keeping everything else constant.
The causal effect is the magnitude by which Y is changed by the unit change in T and not the other way around:
Causal effect = E [Y | do(T=1)] – E [Y | do (T = 0)] (Judea Pearl’s Do-Calculus)
Causal Inference requires domain knowledge, assumptions, and expertise. The Microsoft ALICE Research team has developed DoWhy and EconML open-source libraries to make our life easier. The first step in any causal analysis is posing a clear question:
- What treatment/action am I interested in?
- What outcome do I want to consider?
- What confounders might be correlated with both my outcome and my treatment?
Causal Analysis pipeline: Deep Learning based End-End Causal Inference (DECI) (Microsoft patent).
Causal Discovery – Causal Identification – Causal Estimation – Causal Validation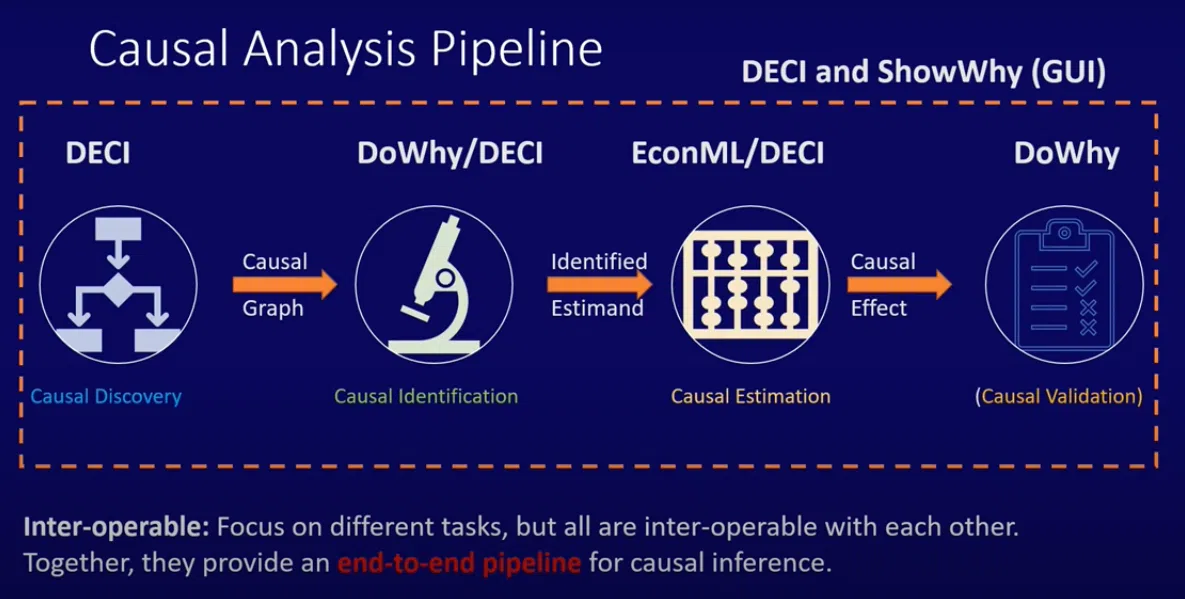
Responsible AI Dashboard in (Azure Machine Learning Studio): Causal Analysis
This feature is based on interpreting fitted models from Model Registry and can explore what might have been the case if there was a Causal understanding of the same variables. We can look at the causal effects of different features and compare them with heterogeneous effects, and we can look at different cohorts and what features or policies would work best for them.
- DECI provides a framework for end-end causal Inference, which can also be used for Discovery or Estimation alone.
- EconML provides multiple causation Estimation methods.
- DoWhy provides multiple Identification and Validation methods.
- ShowWhy provides a no-code End–to–end causal analysis in a user-friendly GUI for causal decision-making.




Hari Hara Bhagavathula is an Applied Machine Learning Researcher at Anblicks and has been in data science profession since 2016. Providing solutions on Marketing and Finance Data science applications with decision making under uncertainty. My research interests are in social science and econometrics problems, conducting Experimentations with Simulations and responsible automatic decision-making systems.

